-
Multiway Non-rigid Point Cloud Registration via Learned Functional Map Synchronization
T-PAMI 2022 : Transactions in Pattern Analysis and Machine Intelligence, 2022
Jiahui Huang, Tolga Birdal, Zan Gojcic, Leonidas Guibas, and Shi-Min Hu
We present SyNoRiM, a novel way to jointly register multiple non-rigid shapes by synchronizing the maps relating learned functions defined on the point clouds. Even though the ability to process non-rigid shapes is critical in various applications ranging from computer animation to 3D digitization, the literature still lacks a robust and flexible framework to match and align a collection of real, noisy scans observed under occlusions. Given a set of such point clouds, our method first computes the pairwise correspondences parameterized via functional maps. We simultaneously learn potentially non-orthogonal basis functions to effectively regularize the deformations, while handling the occlusions in an elegant way. To maximally benefit from the multi-way information provided by the inferred pairwise deformation fields, we synchronize the pairwise functional maps into a cycle-consistent whole thanks to our novel and principled optimization formulation. We demonstrate via extensive experiments that our method achieves a state-of-the-art performance in registration accuracy, while being flexible and efficient as we handle both non-rigid and multi-body cases in a unified framework and avoid the costly optimization over point-wise permutations by the use of basis function maps.
Article in PDF
-
Deep Bingham Networks: Dealing with Uncertainty and Ambiguity in Pose Estimation
IJCV 2022 : International Journal of Computer Vision, 2022
Haowen Deng, Mai Bui, Nassir Navab, Leonidas Guibas, Slobodan Ilic, Tolga Birdal
In this work, we introduce Deep Bingham Networks (DBN), a generic framework that can naturally handle pose-related uncertainties and ambiguities arising in almost all real life applications concerning 3D data. While existing works strive to find a single solution to the pose estimation problem, we make peace with the ambiguities causing high uncertainty around which solutions to identify as the best. Instead, we report a family of poses which capture the nature of the solution space. DBN extends the state of the art direct pose regression networks by (i) a multi-hypotheses prediction head which can yield different distribution modes; and (ii) novel loss functions that benefit from Bingham distributions on rotations. This way, DBN can work both in unambiguous cases providing uncertainty information, and in ambiguous scenes where an uncertainty per mode is desired. On a technical front, our network regresses continuous Bingham mixture models and is applicable to both 2D data such as images and to 3D data such as point clouds. We proposed new training strategies so as to avoid mode or posterior collapse during training and to improve numerical stability. Our methods are thoroughly tested on two different applications exploiting two different modalities: (i) 6D camera relocalization from images; and (ii) object pose estimation from 3D point clouds, demonstrating decent advantages over the state of the art. For the former we contributed our own dataset composed of five indoor scenes where it is unavoidable to capture images corresponding to views that are hard to uniquely identify. For the latter we achieve the top results especially for symmetric objects of ModelNet dataset.
Article in PDF / Project Page
-
HuMoR: 3D Human Motion Model for Robust Pose Estimation
ICCV 2021 : IEEE International Conference on Computer Vision, Online, 2021 (Spotlight)
Davis Rempe, Tolga Birdal, Aaron Hertzmann, Jimei Yang, Srinath Sridhar, and Leonidas Guibas
We introduce HuMoR: a 3D Human Motion Model for Robust Estimation of temporal pose and shape. Though substantial progress has been made in estimating 3D human motion and shape from dynamic observations, recovering plausible pose sequences in the presence of noise and occlusions remains a challenge. For this purpose, we propose an expressive generative model in the form of a conditional variational autoencoder, which learns a distribution of the change in pose at each step of a motion sequence. Furthermore, we introduce a flexible optimization-based approach that leverages HuMoR as a motion prior to robustly estimate plausible pose and shape from ambiguous observations. Through extensive evaluations, we demonstrate that our model generalizes to diverse motions and body shapes after training on a large motion capture dataset, and enables motion reconstruction from multiple input modalities including 3D keypoints and RGB(-D) videos.
Article in PDF / Project Page
-
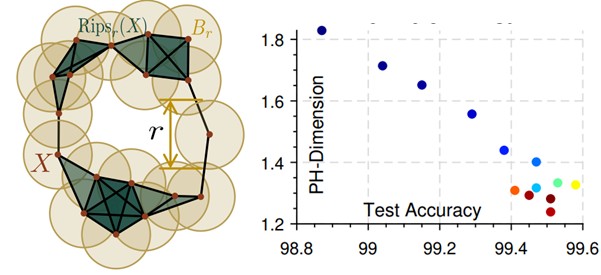
Intrinsic dimension, persistent homology and generalization in neural networks
NeurIPS 2021 : Conference on Neural Information Processing Systems, Online, 2021
Tolga Birdal, Aaron Lou, Leonidas Guibas, and Umut Şimşekli
Disobeying the classical wisdom of statistical learning theory, modern deep neural networks generalize well even though they typically contain millions of parameters. Recently, it has been shown that the trajectories of iterative optimization algorithms can possess \emph{fractal structures}, and their generalization error can be formally linked to the complexity of such fractals. This complexity is measured by the fractal's \emph{intrinsic dimension}, a quantity usually much smaller than the number of parameters in the network. Even though this perspective provides an explanation for why overparametrized networks would not overfit, computing the intrinsic dimension (\eg, for monitoring generalization during training) is a notoriously difficult task, where existing methods typically fail even in moderate ambient dimensions. In this study, we consider this problem from the lens of topological data analysis (TDA) and develop a generic computational tool that is built on rigorous mathematical foundations. By making a novel connection between learning theory and TDA, we first illustrate that the generalization error can be equivalently bounded in terms of a notion called the 'persistent homology dimension' (PHD), where, compared with prior work, our approach does not require any additional geometrical or statistical assumptions on the training dynamics. Then, by utilizing recently established theoretical results and TDA tools, we develop an efficient algorithm to estimate PHD in the scale of modern deep neural networks and further provide visualization tools to help understand generalization in deep learning. Our experiments show that the proposed approach can efficiently compute a network's intrinsic dimension in a variety of settings, which is predictive of the generalization error.
Article in PDF
-
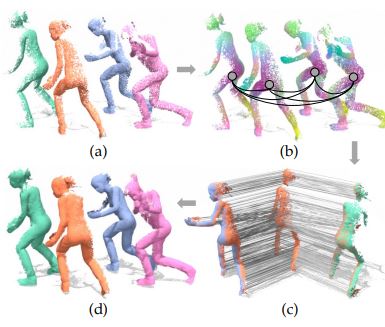
MultiBodySync: Multi-Body Segmentation and Motion Estimation via 3D Scan Synchronization
CVPR 2021 : IEEE Conference on Computer Vision and Pattern Recognition, Online, 2020 (Oral)
Jiahui Huang, He Wang, Tolga Birdal, Minhyuk Sung, Federica Arrigoni, Shi-Min Hu, and Leonidas Guibas
We present MultiBodySync, a novel, end-to-end trainable multi-body motion segmentation and rigid registration framework for multiple input 3D point clouds. The two non-trivial challenges posed by this multi-scan multibody setting that we investigate are: (i) guaranteeing correspondence and segmentation consistency across multiple input point clouds capturing different spatial arrangements of bodies or body parts; and (ii) obtaining robust motion-based rigid body segmentation applicable to novel object categories. We propose an approach to address these issues that incorporates spectral synchronization into an iterative deep declarative network, so as to simultaneously recover consistent correspondences as well as motion segmentation. At the same time, by explicitly disentangling the correspondence and motion segmentation estimation modules, we achieve strong generalizability across different object categories. Our extensive evaluations demonstrate that our method is effective on various datasets ranging from rigid parts in articulated objects to individually moving objects in a 3D scene, be it single-view or full point clouds.
Article in PDF / Source Code
-
Weakly Supervised Learning of Rigid 3D Scene Flow
CVPR 2021: IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2021 (Oral)
Zan Gojcic, Or Litany, Andreas Wieser, Leonidas Guibas, and Tolga Birdal
We propose a data-driven scene flow estimation algorithm exploiting the observation that many 3D scenes can be explained by a collection of agents moving as rigid bodies. At the core of our method lies a deep architecture able to reason at the \textbf{object-level} by considering 3D scene flow in conjunction with other 3D tasks. This object level abstraction, enables us to relax the requirement for dense scene flow supervision with simpler binary background segmentation mask and ego-motion annotations. Our mild supervision requirements make our method well suited for recently released massive data collections for autonomous driving, which do not contain dense scene flow annotations. As output, our model provides low-level cues like pointwise flow and higher-level cues such as holistic scene understanding at the level of rigid objects. We further propose a test-time optimization refining the predicted rigid scene flow. We showcase the effectiveness and generalization capacity of our method on four different autonomous driving datasets.
Article in PDF / Project Page
-
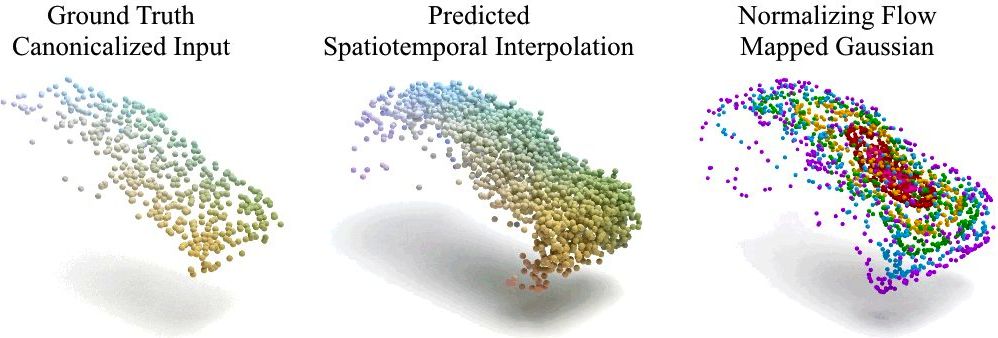
CaSPR: Learning Canonical Spatiotemporal Point Cloud Representations
NeurIPS 2020 : Conference on Neural Information Processing Systems, Online, 2020 (Spotlight)
Davis Rempe, Tolga Birdal, Yongheng Zhao, Zan Gojcic, Srinath Sridhar, and Leonidas JGuibas
We propose CaSPR, a method to learn object-centric Canonical Spatiotemporal Point Cloud Representations of dynamically moving or evolving objects. Our goal is to enable information aggregation over time and the interrogation of object state at any spatiotemporal neighborhood in the past, observed or not. Different from previous work, CaSPR learns representations that support spacetime continuity, are robust to variable and irregularly spacetime-sampled point clouds, and generalize to unseen object instances. Our approach divides the problem into two subtasks. First, we explicitly encode time by mapping an input point cloud sequence to a spatiotemporally-canonicalized object space. We then leverage this canonicalization to learn a spatiotemporal latent representation using neural ordinary differential equations and a generative model of dynamically evolving shapes using continuous normalizing flows. We demonstrate the effectiveness of our method on several applications including shape reconstruction, camera pose estimation, continuous spatiotemporal sequence reconstruction, and correspondence estimation from irregularly or intermittently sampled observations.
Article in PDF / Project Page
-
Quaternion Equivariant Capsule Networks for 3D Point Clouds
ECCV 2020 : European Conference on Computer Vision, Online, 2020 (Oral)
Yongheng Zhao *, Tolga Birdal *, Jan Eric Lenssen, Emanuele Menegatti, Leonidas Guibas and Federico Tombari
We present a 3D capsule architecture for processing of point clouds that is equivariant with respect to the rotation group, translation and permutation of the unordered input sets. The network operates on a sparse set of local reference frames, computed from an input point cloud and establishes end-to-end equivariance through a novel 3D quaternion group capsule layer, including an equivariant dynamic routing procedure. The capsule layer enables us to disentangle geometry from pose, paving the way for more informative descriptions and a structured latent space. In the process, we theoretically connect the process of dynamic routing between capsules to the well-known Weiszfeld algorithm, a scheme for solving\emph {iterative re-weighted least squares (IRLS)} problems with provable convergence properties, enabling robust pose estimation between capsule layers. Due to the sparse equivariant quaternion capsules, our architecture allows joint object classification and orientation estimation, which we validate empirically on common benchmark datasets.
Article in PDF / Source Code
-
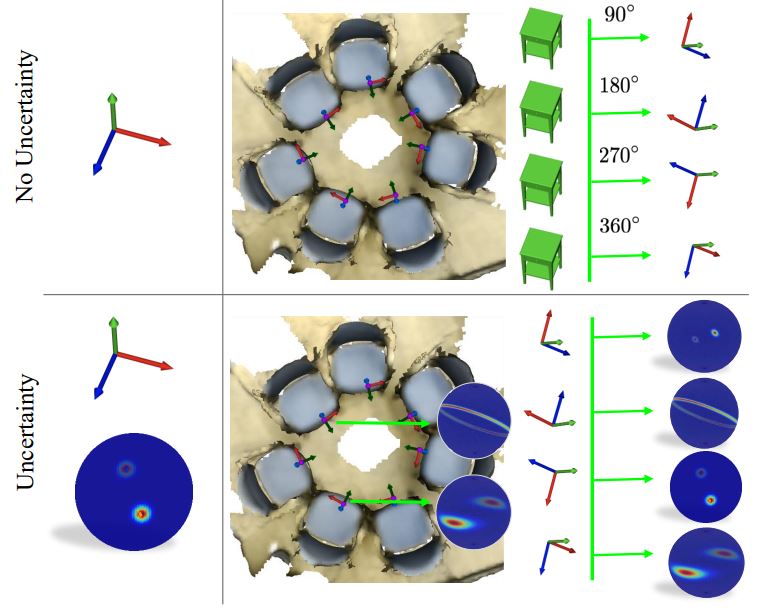
6D Camera Relocalization in Ambiguous Scenes via Continuous Multimodal Inference
ECCV 2020 : European Conference on Computer Vision, Online, 2020 (Oral)
Mai Bui, Tolga Birdal, Haowen Deng, Shadi Albarqouni, Leonidas Guibas, Slobodan Ilic and Nassir Navab
We present a multimodal camera relocalization framework that captures ambiguities and uncertainties with continuous mixture models defined on the manifold of camera poses. In highly ambiguous environments, which can easily arise due to symmetries and repetitive structures in the scene, computing one plausible solution (what most state-of-the-art methods currently regress) may not be sufficient. Instead we predict multiple camera pose hypotheses as well as the respective uncertainty for each prediction. Towards this aim, we use Bingham distributions, to model the orientation of the camera pose, and a multivariate Gaussian to model the position, with an end-to-end deep neural network. By incorporating a Winner-Takes-All training scheme, we finally obtain a mixture model that is well suited for explaining ambiguities in the scene, yet does not suffer from mode collapse, a common problem with mixture density networks. We introduce a new dataset specifically designed to foster camera localization research in ambiguous environments and exhaustively evaluate our method on synthetic as well as real data on both ambiguous scenes and on non-ambiguous benchmark datasets.
Article in PDF / Project Page
-
Deformation-Aware 3D Shape Embedding and Retrieval
ECCV 2020 : European Conference on Computer Vision, Online, 2020 (Oral)
Mikaela Angelina Uy, Jingwei Huang, Minhyuk Sung, Tolga Birdal and Leonidas Guibas
We introduce a new problem of retrieving 3D models that are deformable to a given query shape and present a novel deep deformation-aware embedding to solve this retrieval task. 3D model retrieval is a fundamental operation for recovering a clean and complete 3D model from a noisy and partial 3D scan. However, given a finite collection of 3D shapes, even the closest model to a query may not be satisfactory. This motivates us to apply 3D model deformation techniques to adapt the retrieved model so as to better fit the query. Yet, certain restrictions are enforced in most 3D deformation techniques to preserve important features of the original model that prevent a perfect fitting of the deformed model to the query. This gap between the deformed model and the query induces asymmetric relationships among the models, which cannot be handled by typical metric learning techniques. Thus, to retrieve the best models for fitting, we propose a novel deep embedding approach that learns the asymmetric relationships by leveraging location-dependent egocentric distance fields. We also propose two strategies for training the embedding network. We demonstrate that both of these approaches outperform other baselines in our experiments with both synthetic and real data.
Article in PDF / Project Page
-
Synchronizing Probability Measures on Rotations via Optimal Transport
CVPR 2020: IEEE Conference on Computer Vision and Pattern Recognition, Online, 2020
Tolga Birdal, Michael Arbel, Umut Şimşekli, Leonidas Guibas
We introduce a new paradigm, measure synchronization, for synchronizing graphs with measure-valued edges. We formulate this problem as maximization of the cycle-consistency in the space of probability measures over relative rotations. In particular, we aim at estimating marginal distributions of absolute orientations by synchronizing the conditional ones, which are defined on the Riemannian manifold of quaternions. Such graph optimization on distributions-on-manifolds enables a natural treatment of multimodal hypotheses, ambiguities and uncertainties arising in many computer vision applications such as SLAM, SfM, and object pose estimation. We first formally define the problem as a generalization of the classical rotation graph synchronization, where in our case the vertices denote probability measures over rotations. We then measure the quality of the synchronization by using Sinkhorn divergences, which reduces to other popular metrics such as Wasserstein distance or the maximum mean discrepancy as limit cases. We propose a nonparametric Riemannian particle optimization approach to solve the problem. Even though the problem is non-convex, by drawing a connection to the recently proposed sparse optimization methods, we show that the proposed algorithm converges to the global optimum in a special case of the problem under certain conditions. Our qualitative and quantitative experiments show the validity of our approach and we bring in new perspectives to the study of synchronization.
Article in PDF / Project Page
-
Learning Multiview 3D Point Cloud Registration
CVPR 2020: IEEE Conference on Computer Vision and Pattern Recognition, Online, 2020
Zan Gojcic, Caifa Zhou, Jan D Wegner, Leonidas J Guibas and
Tolga Birdal
We present a novel, end-to-end learnable, multiview 3D point cloud registration algorithm. Registration of multiple scans typically follows a two-stage pipeline: the initial pairwise alignment and the globally consistent refinement. The former is often ambiguous due to the low overlap of neighboring point clouds, symmetries and repetitive scene parts. Therefore, the latter global refinement aims at establishing the cyclic consistency across multiple scans and helps in resolving the ambiguous cases. In this paper we propose, to the best of our knowledge, the first end-to-end algorithm for joint learning of both parts of this two-stage problem. Experimental evaluation on well accepted benchmark datasets shows that our approach outperforms the state-of-the-art by a significant margin, while being end-to-end trainable and computationally less costly. Moreover, we present detailed analysis and an ablation study that validate the novel components of our approach. The source code and pretrained models are publicly available under.
Article in PDF / Source Code
-
From Planes to Corners: Multi-Purpose Primitive Detection in Unorganized 3D Point Clouds
RA-Letters 2020: IEEE Robotics and Automation Letters, 2020
Christiane Sommer, Yumin Sun, Leonidas Guibas, Daniel Cremers, Tolga Birdal
We propose a new method for segmentation-free joint estimation of orthogonal planes, their intersection lines, relationship graph and corners lying at the intersection of three orthogonal planes. Such unified scene exploration under orthogonality allows for multitudes of applications such as semantic plane detection or local and global scan alignment, which in turn can aid robot localization or grasping tasks. Our two-stage pipeline involves a rough yet joint estimation of orthogonal planes followed by a subsequent joint refinement of plane parameters respecting their orthogonality relations. We form a graph of these primitives, paving the way to the extraction of further reliable features: lines and corners. Our experiments demonstrate the validity of our approach in numerous scenarios from wall detection to 6D tracking, both on synthetic and real data.
Article in PDF / Source Code
-
Explaining the Ambiguity of Object Detection and 6D Pose from Visual Data
ICCV 2019: IEEE International Conference on Computer Vision, Seoul, Korea, 2019
Fabian Manhardt, Diego Martin Arroyo, Christian Rupprecht, Benjamin Busam, Tolga Birdal, Nassir Navab and Federico Tombari
3D object detection and pose estimation from a single image are two inherently ambiguous problems. Oftentimes, objects appear similar from different viewpoints due to shape symmetries, occlusion and repetitive textures. This ambiguity in both detection and pose estimation means that an object instance can be perfectly described by several different poses and even classes. In this work we propose to explicitly deal with this uncertainty. For each object instance we predict multiple pose and class outcomes to estimate the specific pose distribution generated by symmetries and repetitive textures. The distribution collapses to a single outcome when the visual appearance uniquely identifies just one valid pose. We show the benefits of our approach which provides not only a better explanation for pose ambiguity, but also a higher accuracy in terms of pose estimation.
Article in PDF
-
Probabilistic Permutation Synchronization using the Riemannian Structure of the Birkhoff Polytope
CVPR 2019: IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019 (Best Paper Candidate)
Tolga Birdal and Umut Şimşekli
We present an entirely new geometric and probabilistic approach to synchronization of correspondences across multiple sets of objects or images. In particular, we present two algorithms:(1) Birkhoff-Riemannian L-BFGS for optimizing the relaxed version of the combinatorially intractable cycle consistency loss in a principled manner,(2) Birkhoff-Riemannian Langevin Monte Carlo for generating samples on the Birkhoff Polytope and estimating the confidence of the found solutions. To this end, we first introduce the very recently developed Riemannian geometry of the Birkhoff Polytope. Next, we introduce a new probabilistic synchronization model in the form of a Markov Random Field (MRF). Finally, based on the first order retraction operators, we formulate our problem as simulating a stochastic differential equation and devise new integrators. We show on both synthetic and real datasets that we achieve high quality multi-graph matching results with faster convergence and reliable confidence/uncertainty estimates.
Article in PDF / Project Page
-
Generic Primitive Detection in Point Clouds Using Novel Minimal Quadric Fits
T-PAMI 2019: IEEE Transactions on pattern analysis and machine intelligence
Tolga Birdal, Benjamin Busam, Nassir Navab, Slobodan Ilic and Peter Sturm
We present a novel and effective method for detecting 3D primitives in cluttered, unorganized point clouds, without axillary segmentation or type specification. We consider the quadric surfaces for encapsulating the basic building blocks of our environments in a unified fashion. We begin by contributing two novel quadric fits targeting 3D point sets that are endowed with tangent space information. Based upon the idea of aligning the quadric gradients with the surface normals, our first formulation is exact and requires as low as four oriented points. The second fit approximates the first, and reduces the computational effort. We theoretically analyze these fits with rigor, and give algebraic and geometric arguments. Next, by re-parameterizing the solution, we devise a new local Hough voting scheme on the null-space coefficients that is combined with RANSAC, reducing the complexity from O(N^4) to O(N^3) (three-points). To the best of our knowledge, this is the first method capable of performing a generic cross-type multi-object primitive detection in difficult scenes without segmentation. Our extensive qualitative and quantitative results show that our method is efficient and flexible, as well as being accurate.
Article in PDF
-
3D Local Features for Direct Pairwise Registration
CVPR 2019: IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019
Haowen Deng, Tolga Birdal and Slobodan Ilic
We present a novel, data driven approach for solving the problem of registration of two point cloud scans. Our approach is direct in the sense that a single pair of corresponding local patches already provides the necessary transformation cue for the global registration. To achieve that, we first endow the state of the art PPF-FoldNet auto-encoder (AE) with a pose-variant sibling, where the discrepancy between the two leads to pose-specific descriptors. Based upon this, we introduce RelativeNet, a relative pose estimation network to assign correspondence-specific orientations to the keypoints, eliminating any local reference frame computations. Finally, we devise a simple yet effective hypothesize-and-verify algorithm to quickly use the predictions and align two point sets. Our extensive quantitative and qualitative experiments suggests that our approach outperforms the state of the art in challenging real datasets of pairwise registration and that augmenting the keypoints with local pose information leads to better generalization and a dramatic speed-up.
Article in PDF
-
3D Point Capsule Networks
CVPR 2019: IEEE Conference on Computer Vision and Pattern Recognition, Long Beach, USA, 2019
Yongheng Zhao, Tolga Birdal, Haowen Deng and Federico Tombari
In this paper, we propose 3D point-capsule networks, an auto-encoder designed to process sparse 3D point clouds while preserving spatial arrangements of the input data. 3D capsule networks arise as a direct consequence of our unified formulation of the common 3D auto-encoders. The dynamic routing scheme and the peculiar 2D latent space deployed by our capsule networks bring in improvements for several common point cloud-related tasks, such as object classification, object reconstruction and part segmentation as substantiated by our extensive evaluations. Moreover, it enables new applications such as part interpolation and replacement.
Article in PDF / Source Code
-
Bayesian Pose Graph Optimization via Bingham Distributions and Tempered Geodesic MCMC
NeurIPS 2018: 32nd Conference on Neural Information Processing Systems, Montréal, Canada, 2018
Tolga Birdal, Umut Şimşekli, M. Onur Eken and Slobodan Ilic
We introduce Tempered Geodesic Markov Chain Monte Carlo (TG-MCMC) algorithm for initializing pose graph optimization problems, arising in various scenarios such as SFM (structure from motion) or SLAM (simultaneous localization and mapping). TG-MCMC is first of its kind as it unites global non-convex optimization on the spherical manifold of quaternions with posterior sampling, in order to provide both reliable initial poses and uncertainty estimates that are informative about the quality of solutions. We devise theoretical convergence guarantees and extensively evaluate our method on synthetic and real benchmarks. Besides its elegance in formulation and theory, we show that our method is robust to missing data, noise and the estimated uncertainties capture intuitive properties of the data.
Article in PDF
-
A Minimalist Approach to Type-Agnostic Detection of Quadrics in Point Clouds
CVPR 2018: IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, US, 2018
Tolga Birdal, Benjamin Busam, Nassir Navab, Slobodan Ilic and Peter Sturm
This paper proposes a segmentation-free, automatic and efficient procedure to detect general geometric quadric forms in point clouds, where clutter and occlusions are inevitable. Our everyday world is dominated by man-made objects which are designed using 3D primitives (such as planes, cones, spheres, cylinders, etc.). These objects are also omnipresent in industrial environments. This gives rise to the possibility of abstracting 3D scenes through primitives, thereby positions these geometric forms as an integral part of perception and high level 3D scene understanding.
As opposed to state-of-the-art, where a tailored algorithm treats each primitive type separately, we propose to encapsulate all types in a single robust detection procedure. At the center of our approach lies a closed form 3D quadric fit, operating in both primal & dual spaces and requiring as low as 4 oriented-points. Around this fit, we design a novel, local null-space voting strategy to reduce the 4-point case to 3. Voting is coupled with the famous RANSAC and makes our algorithm orders of magnitude faster than its conventional counterparts. This is the first method capable of performing a generic cross-type multi-object primitive detection in difficult scenes. Results on synthetic and real datasets support the validity of our method
Article in PDF
-
PPF-FoldNet: Unsupervised Learning of Rotation Invariant 3D Local Descriptors
ECCV 2018: European Conference on Computer Vision, Munich, Germany, 2018
Haowen Deng, Tolga Birdal, Slobodan Ilic
We present PPF-FoldNet for unsupervised learning of 3D local descriptors on pure point cloud geometry. Based on the folding-based auto-encoding
of well known point pair features, PPF-FoldNet offers many desirable properties:
it necessitates neither supervision, nor a sensitive local reference frame, benefits
from point-set sparsity, is end-to-end, fast, and can extract powerful rotation invariant descriptors. Thanks to a novel feature visualization, its evolution can be
monitored to provide interpretable insights. Our extensive experiments demonstrate that despite having six degree-of-freedom invariance and lack of training
labels, our network achieves state of the art results in standard benchmark datasets
and outperforms its competitors when rotations and varying point densities are
present. PPF-FoldNet achieves 9% higher recall on standard benchmarks, 23%
higher recall when rotations are introduced into the same datasets and finally, a
margin of
> 35% is attained when point density is significantly decreased.
Article in PDF
-
PPFNet: Global Context Aware Local Features for Robust 3D Point Matching
CVPR 2018: IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, US, 2018
Haowen Deng, Tolga Birdal, Slobodan Ilic
We present PPFNet - Point Pair Feature NETwork for deeply learning a globally informed 3D local feature descriptor to find correspondences in unorganized point clouds. PPFNet learns local descriptors on pure geometry and is highly aware of the global context, an important cue in deep learning. Our 3D representation is computed as a collection of point-pair-features combined with the points and normals within a local vicinity. Our permutation invariant network design is inspired by PointNet and sets PPFNet to be ordering-free. As opposed to voxelization, our method is able to consume raw point clouds to exploit the full sparsity. PPFNet uses a novel N-tuple loss and architecture injecting the global information naturally into the local descriptor. It shows that context awareness also boosts the local feature representation. Qualitative and quantitative evaluations of our network suggest increased recall, improved robustness and invariance as well as a vital step in the 3D descriptor extraction performance.
Article in PDF
-
Survey of Higher Order Rigid Body Motion Interpolation Methods for Keyframe Animation and Continuous-Time Trajectory Estimation
3DV 2018: International Conference on 3D Vision, Verona, Italy, 2018
Adrian Haarbach, Tolga Birdal, Slobodan Ilic
In this survey we carefully analyze the characteristics of higher order rigid body motion interpolation methods to obtain a continuous trajectory from a discrete set of poses. We first discuss the tradeoff between continuity, local control and approximation of classical Euclidean interpolation schemes such as Bezier and B-splines. The benefits of the manifold of unit quaternions SU(2), a double-cover of rotation matrices SO(3), as rotation parameterization are presented, which allow for an elegant formulation of higher order orientation interpolation with easy analytic derivatives, made possible through the Lie Algebra su(2) of pure quaternions and the cumulative form of cubic B-splines. The same construction scheme is then applied for joint interpolation in the full rigid body pose space, which had previously been done for the matrix representation SE(3) and its twists, but not for the more efficient unit dual quaternion DH1 and its screw motions. Both suffer from the effects of coupling translation and rotation that have mostly been ignored by previous work. We thus conclude that split interpolation in R3 × SU(2) is preferable for most applications. Our final runtime experiments show that joint interpolation in SE(3) is 2 times and in DH1 1.3 times slower - which furthermore justifies our suggestion from a practical point of view.
Article in PDF / Project Page
-
CAD Priors for Accurate and Flexible Instance Reconstruction
ICCV 2017: IEEE International Conference on Computer Vision, Venice, Italy, 2017
Tolga Birdal, Slobodan Ilic
We present an efficient and automatic approach for accurate instance reconstruction of big 3D objects from multiple, unorganized and unstructured point clouds, in presence of dynamic clutter and occlusions. In contrast to conventional scanning, where the background is assumed to be rather static, we aim at handling dynamic clutter where the background drastically changes during object scanning. Currently, it is tedious to solve this problem with available methods unless the object of interest is first segmented out from the rest of the scene. We address the problem by assuming the availability of a prior CAD model, roughly resembling the object to be reconstructed. This assumption almost always holds in applications such as industrial inspection or reverse engineering. With aid of this prior acting as a proxy, we propose a fully enhanced pipeline, capable of automatically detecting and segmenting the object of interest from scenes and creating a pose graph, online, with linear complexity. This allows initial scan alignment to the CAD model space, which is then refined without the CAD constraint to fully recover a high fidelity 3D reconstruction, accurate up to the sensor noise level. We also contribute a novel object detection method, local implicit shape models (LISM) and give a fast verification scheme. We evaluate our method on multiple datasets, demonstrating the ability to accurately reconstruct objects from small sizes up to 125m3.
Article in PDF
-
Camera Pose Filtering with Local Regression Geodesics on the Riemannian Manifold of Dual Quaternions
ICCV 2017 Workshop on Multiview Relationships in 3D Data, Venice, Italy, 2017
Benjamin Busam, Tolga Birdal and Slobodan Ilic
Time-varying, smooth trajectory estimation is of great interest to the vision community for accurate and well behaving 3D systems. In this paper, we propose a novel principal component local regression filter acting directly on the Riemannian manifold of unit dual quaternions DH1. We use a numerically stable Lie algebra of the dual quaternions together with exp and log operators to locally linearize the 6D pose space. Unlike state of the art path smoothing methods which either operate on SO(3) of rotation matrices or the hypersphere H1 of quaternions, we treat the orientation and translation jointly on the dual quaternion quadric in the 7-dimensional real projective space RP7. We provide an outlier-robust IRLS algorithm for generic pose filtering exploiting this manifold structure. Besides our theoretical analysis, our experiments on synthetic and real data show the practical advantages of the manifold aware filtering on pose tracking and smoothing.
Article in PDF
-
A Point Sampling Algorithm for 3D Matching of Irregular Geometries
IROS 2017: IEEE International Conference on Computer Vision, Vancouver, Canada, 2017
Tolga Birdal, Slobodan Ilic
We present a 3D mesh re-sampling algorithm, carefully tailored for 3D object detection using point pair features (PPF). Computing a sparse representation of objects is critical for the success of state-of-the-art object detection, recognition and pose estimation methods. Yet, sparsity needs to preserve fidelity. To this end, we develop a simple, yet very effective point sampling strategy for detection of any CAD model through geometric hashing. Our approach relies on rendering the object coordinates from a set of views evenly distributed on a sphere. Actual sampling takes place on 2D domain over these renderings; the resulting samples are efficiently merged in 3D with the aid of a special voxel structure and relaxed with Lloyd iterations. The generated vertices are not concentrated only on critical points, as in many keypoint extraction algorithms, and there is even spacing between selected vertices. This is valuable for quantization based detection methods, such as geometric hashing of point pair features. The algorithm is fast and can easily handle the elongated/acute triangles and sharp edges typically existent in industrial CAD models, while automatically pruning the invisible structures. We do not introduce structural changes such as smoothing or interpolation and sample the normals on the original CAD model, achieving the maximum fidelity. We demonstrate the strength of this approach on 3D object detection in comparison to similar sampling algorithms.
Article in PDF
-
X-Tag: A Fiducial Tag for Flexible and Accurate Bundle Adjustment
3DV 2016: IEEE International Conference on 3D Vision (3DV), Stanford, CA, 2016
Tolga Birdal, Ievgeniia Dobryden, Slobodan Ilic
In this paper we design a novel planar 2D fiducial
marker and develop fast detection algorithm aiming easy camera calibration and precise 3D reconstruction at the marker locations via the bundle adjustment. Even though an abundance of planar fiducial markers have been made and used in various tasks, none of them has properties necessary to solve the aforementioned tasks. Our marker, Xtag, enjoys a novel design, coupled with very efficient and robust detection scheme, resulting in a reduced number of false positives. This is achieved by constructing markers with random circular features in the image domain and encoding them using two true perspective invariants: crossratios and intersection preservation constraints. To detect the markers, we developed an effective search scheme, similar to Geometric Hashing and Hough Voting, in which the marker decoding is cast as a retrieval problem. We apply our system to the task of camera calibration and bundle adjustment. With qualitative and quantitative experiments, we demonstrate the robustness and accuracy of X-tag in spite of blur, noise, perspective and radial distortions, and showcase camera calibration, bundle adjustment and 3d fusion of depth data from precise extrinsic camera poses.
Article in PDF
-
Online Inspection of 3D Parts via a Locally Overlapping Camera Network
WACV 2016: IEEE Winter Conference on Applications of Computer Vision
Tolga Birdal, Emrah Bala, Tolga Eren, Slobodan Ilic
The raising standards in manufacturing demands reliable and fast industrial quality control mechanisms. This
paper proposes an accurate, yet easy to install multi-view,
close range optical metrology system, which is suited to online operation. The system is composed of multiple static,
locally overlapping cameras forming a network. Initially,
these cameras are calibrated to obtain a global coordinate
frame. During run-time, the measurements are performed
via a novel geometry extraction techniques coupled with an
elegant projective registration framework, where 3D to 2D
fitting energies are minimized. Finally, a non-linear regression is carried out to compensa te for the uncontrollable errors. We apply our pipeline to inspect various geometrical structures found on automobile parts. While presenting
the implementation of an involved 3D metrology system, we
also demonstrate that the resulting inspection is as accurate
as 0 .2 mm, repeatable and much faster, compared to the existing methods such as coordinate measurement machines
(CMM) or ATOS.
Article in PDF
-
Point Pair Features Based Object Detection and Pose Estimation Revisited
3DV 2015: IEEE International Conference on 3D Vision, Lyon, France
Tolga Birdal, Slobodan Ilic
We present a revised pipe-line of the existing 3D object detection and pose estimation framework based on point
pair feature matching. This framework proposed to represent 3D target object using self-similar point pairs, and then
matching such model to 3D scene using efficient Hough-like
voting scheme operating on the reduced pose parameter
space. Even though this work produces great results and
motivated a large number of extensions, it had some general
shortcoming like relatively high dimensionality of the search
space, sensitivity in establishing 3D correspondences, having performance drops in presence of many outliers and low
density surfaces.
In this paper, we explain and address these drawbacks
and propose new solutions within the existing framework. In
particular, we propose to couple the object detection with a
coarse-to-fine segmentation, where each segment is subject
to disjoint pose estimation. During matching, we apply
a weighted Hough voting and an interpolated recovery of
pose parameters. Finally, all the generated hypothesis are
tested via an occlusion-aware ranking and sorted. We argue
that such a combined pipeline simultaneously boosts the
detection rate and reduces the complexity, while improving
the accuracy of the resulting pose. Thanks to such enhanced
pose retrieval, our verification doesn’t necessitate ICP and
thus achieves better compromise of speed vs accuracy. We
demonstrate our method on existing datasets as well as on
our scenes. We conclude that via the new pipe-line, point
pair features can now be used in more challenging scenarios.
Article in PDF
-
A Unified Probabilistic Framework For Robust Decoding Of Linear Barcodes
ICASSP 2015: IEEE International Conference on Acoustics, Speech, and Signal Processing, Brisbane, Australia
Umut Simsekli, Tolga Birdal
Both consumer market and manufacturing industry makes heavy use of 1D (linear) barcodes. From helping the visually impaired to identifying the products to industrial automated industry management, barcodes are the prevalent source of item tracing technology. Because of this ubiquitous use, in recent years, many algorithms have been proposed targeting barcode decoding from high-accessibility devices such as cameras. However, the current methods have at least one of the two major problems: 1) they are sensitive to blur, perspective/lens distortions, and non-linear deformations, which often occur in practice, 2) they are specifically designed for a specific barcode symbology (such as UPC-A) and cannot be applied to other symbologies. In this paper, we aim to address these problems and present a dynamic Bayesian network in order to robustly model all kinds of linear progressive barcodes. We apply our method on various barcode datasets and compare the performance with the state-of-the-art. Our experiments show that, as well as being applicable to all progressive barcode types, our method provides competitive results in clean UPC-A datasets and outperforms the state-of-the-art in difficult scenarios.
Article in PDF
-
Towards A Complete Framework For Deformable Surface Recovery Using RGBD Cameras
IROS'12 Workshop on Color-Depth Fusion in Robotics
Tolga Birdal, Diana Mateus Slobodan Ilic
In this paper, we study the problem of 3D deformable
surface tracking with RGBD cameras, specifically
Microsofts Kinect. In order to achieve this we introduce a
fully automated framework that includes several components:
automatic initialization based on segmentation of the object of
interest, then robust range flow that guides deformations of
the object of interest and finally representation of the results
using mass-spring model. The key contribution is extension of
the range flow work of Spies and Jahne [1] that combines
Lucas-Kanade [2] and Horn and Shunk [3] approaches for
RGB-D data, makes it to converge faster and incorporates color
information with multichannel formulation. We also introduced
a pipeline for generating synthetic data and performed error
analysis and comparison to original range flow approach. The
results show that our method is accurate and precise enough
to track significant deformation smoothly at near real-time performance.
Article in PDF
-
A Novel Method For Image Vectorization
arXiv:1403.0728
Tolga Birdal, Emrah Bala
Vectorization of images is a key concern uniting computer graphics
and computer vision communities. In this paper we are presenting a novel idea for efficient, customizable vectorization of raster
images, based on Catmull Rom spline fitting. The algorithm maintains a good balance between photo-realism and photo abstraction,
and hence is applicable to applications with artistic concerns or applications where less information loss is crucial. The resulting algorithm is fast, parallelizable and can satisfy general soft realtime
requirements. Moreover, the smoothness of the vectorized images
aesthetically outperforms outputs of many polygon-based methods.
Article in PDF
-
Flow Enhancing Line Integral Convolution Filter
ICIP 2010
Tolga Birdal, Emrah Bala
Visualization of vector fields is an operation used in many
fields such as science, art and image processing. Lately, line
integral convolution (LIC) technique [1], which is based on
locally filtering an input image along a curved stream line in
a vector field, has become very popular in this area because of
its local and robust characteristics. For smoothing and texture
generation, used vector field deeply affects the output of LIC
method. We propose a new vector field based on flow fields
to use with LIC. This new hybrid technique is called flow
enhancing line integral convolution filtering (FELIC) and it
is highly capable of smoothing an image and generating high
fidelity textures.
Article in PDF
-
A Factorization Based Recommender System for Online Services (Çevrimiçi Servisler için Ayrısım Tabanlı Tavsiye Sistemi)
SIU 2013 Alper Atalay Best Paper Award Ranked 3
Umut Simsekli, Tolga Birdal, Emre Koc, A. Taylan Cemgil
Along with the growth of the Internet, automatic
recommender systems have become popular. Due to being intuitive and useful, factorization based models, including the
Nonnegative Matrix Factorization (NMF) model, are one of the
most common approaches for building recommender systems. In
this study, we focus on how a recommender system can be built for
online services and how the parameters of an NMF model should
be selected in a recommender system setting. We first present a
general system architecture in which any kind of factorization
model can be used. Then, in order to see how accurate the NMF
model fits the data, we randomly erase some parts of a real data
set that is gathered from an online food ordering service, and
we reconstruct the erased parts by using the NMF model. We
report the mean squared errors for different parameter settings
and different divergences.
Article in PDF
-
Real-time automated road, lane and car detection for autonomous driving
DSP in Cars 2007
Tolga Birdal, Aytul Ercil
In this paper, we discuss a vision-based system for
autonomous guidance of vehicles. An autonomous
intelligent vehicle has to perform a number of
functionalities. Segmentation of the road, determining the
boundaries to drive in and recognizing the vehicles and
obstacles around are the main tasks for vision guided
vehicle navigation. In this article we propose a set of
algorithms, which lead to the solution of road and vehicle
segmentation using data from a color camera. The
algorithms described here combine gray value difference
and texture analysis techniques to segment the road from
the image, several geometric transformations and contour
processing algorithms are used to segment lanes, and
moving cars are extracted with the help of background
modeling and estimation. The techniques developed have
been tested in real road images and the results are
presented.
Article in PDF































 Bilateral Filtering")


































Social Profiles